The term “fake news” was almost non-existent in the general context and media providers prior to October 2016 but times have changed and I would not be surprised if you have heard the term being used today, in the news, the radio or just in the street.
Fake news is a term that has been used to describe very different issues, from satirical articles to completely fabricated news and plain government propaganda in some outlets. Fake news, information bubbles, news manipulation and the lack of trust in the media are growing problems with huge ramifications in our society. However, in order to start addressing this problem, we need to have an understanding on what Fake News is. Only then can we look into the different techniques and fields of machine learning (ML), natural language processing (NLP) and artificial intelligence (AI) that could help us fight this situation.

What is fake news
“Fake news” has been used in a multitude of ways in the last half a year and multiple definitions have been given. For instance, the New York times defines it as “a made-up story with an intention to deceive”. This definition focuses on two dimensions: the intentionality (very difficult to prove) and the fact that the story is made up. This implies that honest mistakes (no matter how major they are, as long as they are accidental) are not considered to be fake news. The challenge lies, of course, on how to prove intentionality. Also, “deceive” is a relatively vague concept that I believe was purposely used by the writer to allow for a multitude of situations to be included in the definition: propaganda, completely fabricated news, partial lies, omissions or unsupported accusations. This shows already one of the major challenges with fake news, measuring it or even defining it properly could very quickly become a subjective matter, rather than an objective metric. Despite all these drawbacks, several people and organisations have tried to categorised fake news in different ways.
First Draft News, an organisation dedicated to improving skills and standards in the reporting and sharing of online information, has recently published a great article that explains the fake news environment and proposes 7 types of fake content:
- False Connection: Headlines, visuals or captions don’t support the content
- False Context: Genuine content is shared with false contextual information
- Manipulated content: Genuine information or imagery is manipulated
- Satire or Parody: No intention to cause harm but potential to fool
- Misleading Content: Misleading use of information to frame an issue/individual
- Imposter Content: Impersonation of genuine sources
- Fabricated content: New content that is 100% false
This is the best and most complete categorisation that I have seen and I know that a lot of work and research have been devoted to compile it.

Before moving to the options that ML/AI/NLP provide us to address these challenges, I think it is worth mentioning why fake news is so prominent today. We might believe that fake news only exists for political advantage, but this is not the only reason. In fact, it might not even be the main one. The reasons behind fake news include media manipulation and propaganda, political and social influence, provocation and social unrest and financial profit. It has been thoroughly reported that a group of Macedonian teenagers could be behind several of the most viral Fake stories prior to the US Presidential election, and their motives seem to be nothing but financial (generating revenue via advertising).
From a pragmatic engineering and research point of view, Fake news is a too general and too vague problem to address directly. For this reason, I am splitting it into smaller, more approachable problems: Fact Checking, Source credibility and Trust, News bias and Misleading headlines.
Fact Checking
Some of the clearest and most objective cases of “Fake News” include incorrect facts that could be checked. This could include lying about the number of immigrants in a country or clearly exaggerated the cost of the national health service for a country. There are more than 114 fact checking initiatives in almost 50 countries. These include Full Fact, a charity in the UK that among other things, fact checks comments made by politicians in the House of Commons and the Crosscheck project from First Draft News that introduces a framework for fact checking that is being tested in the context of the French elections. These organisations are doing an amazing job making sure people are accountable. However, their scale is very limited because they rely on human intervention. Fortunately, the research community has been working for years in different areas that can be used to automate at least part of their work flow. Information and relationship extraction are two fields of NLP that can detect specific nuggets of information being mentioned in natural language. For instance, given the sentence “Tim Cook is the CEO of Microsoft” these type of systems could automatically identify that the article claims that the job of Tim Cook in Microsoft is being the CEO. If the system also had access to information about the company (e.g., companies house or even Wikipedia) this could easily be debunked because the Microsoft’s CEO is Satya Nadella. In addition to the academic efforts, we are seeing different companies starting to apply these technologies for Automatic Fact Checking. One of the best examples of this is Factmata, a start-up closely link to the University College of London (UCL) and its machine learning research. Not only they can detect if specific sentences contain “factual” elements in it, but they also check some of those claims against public knowledge bases and databases.
Source Credibility and trust
In the past, the news cycle was driven by the traditional media outlets (i.e., major newspapers and radio and TV stations). This implied that a certain level of editorial control and rigour was applied and expected. The journalism landscape has changed dramatically in the last decade. Firstly, the amount of content being published has soared with the Washington Post alone publishing close to 1,000 documents a day and globally, more than 1 million blogposts being published every single day. Secondly, virtually everyone with a blog is acting as a journalist, or at least, sharing his/her views of the world; this effect has also been multiplied due to the reach of social media. Finally, the majority of the media is moving towards an advertising based business model where clicks in the article are the main economic drive, and such articles tend to be the most controversial ones.
Under these circumstances, it is critical that we understand how credible different sources are, and then we can apply our own criticism to decide to believe them or to find a second source for this information. However, in a world with thousands of publications either disappearing or being created every minute, this cannot be done manually. One solution could be the creation of a source credibility index providing a score, or at least a rank for different publishers. In fact, some say that quality for news is mostly about solving this reputation issue. The main challenge with this solution is that, in order to be accepted by the journalistic community and the public alike, it will have to be completely transparent and based on objective principles and features. Furthermore, it will have to be politically (and geographically) neutral because labelling sites as “fake news” could have massive implications. Another factor is that it should consider the many sources that mix content with occasional satire (e.g., New Yorker or Guardian).
Another area that could prove to be helpful is graph analysis. Stories are not published in isolation by a given source. Sources with similar political alignment tend to write in the same way, as well as refer to each other or even republish (syndicate) the exact same article. This can be taken one step further if we analyse not only the linking patterns but also the advertising tracker signatures to profile and detect fake news ecosystems. This method is explain in detail in an article from the London School of Economics. I strongly recommend it to everyone interested in news bias and community analysis.
News Bias, Information Bubbles and Polarity
Even before Fake News became a trend, we were aware of the problems and challenges of modern information consumption. Some argue that the media providers have created filter bubbles and “echo chambers” where people’s point of view are reinforced while other points of view are neglected. While I have no doubt they have help create this situation (especially those related to social media platforms) recent studies suggest that our own behaviour and habits are equally to blame because we tend to avoid articles we disagree with.
This might have been one of the causes for the increase in polarisation both in the political and media worlds have been several articles and research articles investigating these phenomenon. For instance, a group of researchers have recently published a paper about quantifying controversy in social media. Other reports suggest that specific sources are driving specific topics of discussion by focusing on controversial ideas.
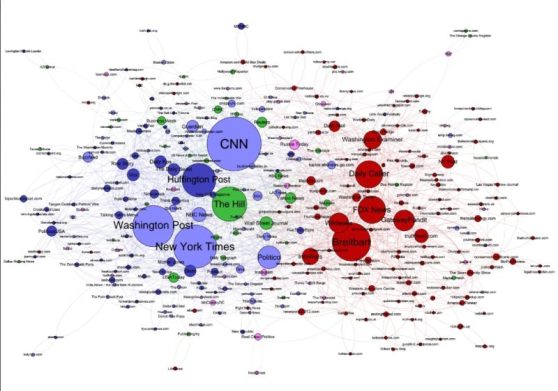
One exciting line of research we are exploring at Signal is the bias of specific sources given a common topic. In other words, how is the coverage of the same topic different for alternative sources. For instance, if we compare the angle of articles about Brexit from UK newspapers in the conservative spectrum against those friendlier to the EU we can see how the language is clearly different. The former talks about freedom, control and greatness when Brexit happens and immigration, lack of control and EU failures if we stay. On the other hand, the pro-european publications focus more on isolation, going back to the past and economic uncertainty and debacle if we leave, while talking about economic greatness, trade increase and moral high ground if we stay. This already shows one of the main challenges with news bias. Neither side is “fake news” nor they can be proven as facts. In this case I suggested a reasonably moderate message, but if we ran a similar analysis with more extreme publications we could see points such as the “colonisation of the UK by foreigners” or a “EU conspiracy to take over the UK and control our fate from Brussels”. I would consider this fake news, but it is extremely complicated for computer system to draw the line between those.
On the bright side, we might not need to do so just yet. The first step is to detect that there is a specific event that is controversial and creates a polarity of opinions. Fortunately, this relates to several areas of research: Clustering can help discovering groups of articles (or sources) that share a similar opinion or refer to the same topic in a similar tone. Depending on how well balanced the different sides are we could also use anomaly detection to investigate the outliers in the fringe zones. In addition, other techniques like graph analysis and sentiment analysis could also support the work done by the clustering models to group instances that not only talk about the same topic but also have a similar sentiment towards it.
Misleading headlines
As explained before, the economic model for media publishers has been shifting towards an advertising based system where encouraging the users to click on stories is the main drive for revenue. Additionally, according to different experiments, we tend to share articles in social media just based on their headline without even reading them ourselves. These factors have led some headlines to provide a completely different perspective than the article itself. This ranges from pure clickbait to exaggerations and hyperboles in headlines to improve readership, and even clear manipulation to change the public perception and create civil unrest.
The research community defines this problem as stance detection. Recently, a group of researchers and journalists have created the Fake News Challenge in order for the community to create better models for its automatic detection. The competition provides a dataset of articles and labels determining if each headline-content pairs agree, disagree, discuss the same topic, or they are completely unrelated. More information about the challenge itself, as well as how AI can help fake news can be found in this blogpost.
Conclusion
Fake news is a problem that is heavily affecting society and our perception of not only the media but also facts and opinions themselves. I believe that this problem is solvable using AI and ML, but it will only be possible if the different communities with expertise about this work together, namely journalists, machine learning experts and product developers. In addition, I strongly believe that very little can be done without dividing the problem into smaller problems and then combining each one of the potential solutions.
From a more general perspective, I believe that the technology will allow a change in the information consumption habits by showing us different points of view for an interesting event and then empowering the user to decide what to believe. This will not only improve our understanding of the world, but also minimise the polarisation in society.

One thought