In the previous post of this series, I focused on how to scale up an AI-first startup from the company perspective because company behaviours will have a deep impact on the effectiveness and success of the organisation as a whole, and the data science function in particular.
This post (which was also published in AI Business) assumes that the company is addressing the points raised in the previous post and focuses on the challenges of developing AI capabilities and scaling a data science function. The impact and efficacy of data science on the business as it scales are directly tied to the following three pillars:
- Product alignment and user value
- Pragmatism and system thinking
- Data and machine learning infrastructure
Each one of these aspects is a factor directly related to the impact data science will have in the organization.
Product alignment and user value
In companies like Signal AI, where we use data science in order to improve our services and products (versus pure research done in universities), it is critical to understand and frame problems around our clients’ needs. Once this is done, the teams can explore potential solutions to these problems using different approaches and areas of expertise. One of my suggestions is to be explicit on your objectives, how to measure success, what assumptions you have made and what are the hypotheses for each experiment or idea.
Clearly coupling data science initiatives and value to users is critical. One common mistake in data science is to work on a local optimisation where a ‘model’ is improved over a long time but the actual value for the user is not only implicit, but also marginal. In some scenarios, the actual impact might even be negative. By framing problems around user value, the teams might find simpler or more effective solutions (potentially without data science).
I believe that, in the majority of industrial cases, the main challenge in data science is not how to solve a problem, but knowing what problem to solve in order to maximise impact.
Pragmatism and System Thinking
Many people working in data science are driven by trying to improve the current best approach on a given problem. This could be the ‘best model’ in production for a company or a state of the art (SOTA) solution in academia. While this might be a good approach for academics and for some industrial problems, it is not the best approach for all organisations.
If you are a scale-up company with AI at your core, you might have several problems you are trying to solve at any given time. For a few of them, usually related to the differentiation or defensibility of the company, it makes complete sense to optimise the models as much as you possibly can, even if it will take months or years to do so. However, for many other data science initiatives, the opportunity cost might be high when spending time on a non-critical component after you have achieved a ‘good enough’ level of value for clients. In many cases, improvements that are not directly perceivable by the users might not be worth investing too much time on. This is not because data science would not be able to help, but rather because there might be other problems with higher return on investment (ROI). The main principle is to not let perfect be the enemy of the good.
Another common issue is defining exactly what constitutes the ‘best’ solution. Quality is just one part of the equation, but other aspects such as efficiency, explainability, ease of deployment and monitoring, or consistency could be as important depending on your problem space. Probably one of the best examples of this is how Netflix learnt a lot from, but never implemented in production, the winner of their famous recommendation challenge.
When using data science to solve a problem in industry, best practice is generally to start with the simplest possible solution that might solve the problem end to end. This is the quickest way to gather information about the problem and the solution. After this, there will be less uncertainty surrounding the problem and the suitability of the potential solution, as well as which aspects are in greatest need of improvement. The ‘simplest’ solution, could be an off-the-shelf model or even a set of simple heuristics. The irony of this advice is that while almost every data scientist would agree this makes sense, many still opt for more complex initial solutions in practice.
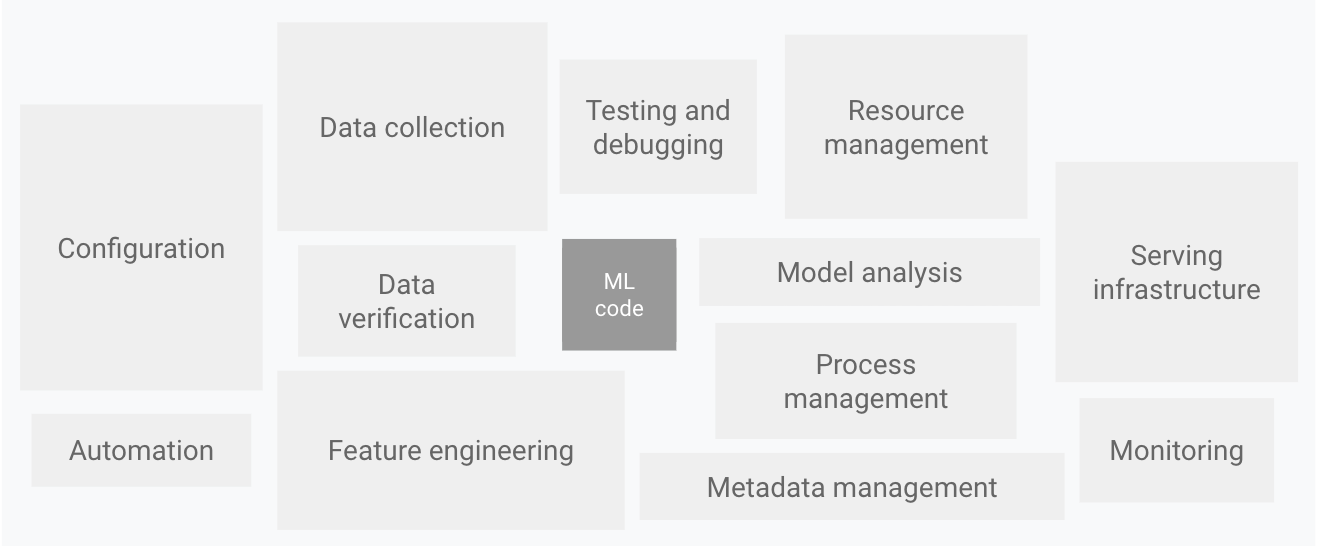
Using system thinking is pivotal because machine learning (ML) models tend to be a small cog in a much larger mechanism, as you can see in the above picture taken from the (great) paper Hidden Technical Debt in Machine Learning Systems. Deployment of models is never the end and model monitoring is as important as model training. Moreover, I would encourage everyone to assume AI systems will make mistakes (because they will) and to create a system that can elegantly deal with, and hopefully learn from, those mistakes.
Infrastructure and ML Ops
Machine learning operations (ML Ops) is one of the trendiest areas at the moment for a good reason. If used effectively, it will be a multiplier for the company’s data science impact. By ensuring it is easy, scalable and safe to deploy and evaluate models, data scientists will run more experiments. In addition, by allowing for the testing, debugging and monitoring of models in production, many problems will be detected more quickly. This could include internal problems (e.g., bugs in some of the models) as well as external factors (e.g., data distribution and topic shift changes).
While ML Ops is becoming more popular, it is still difficult to prioritise this type of work in a growing company. This type of investment will take effort and it will probably be an opportunity cost in the short term. However, it will definitely pay off in the medium and long term. As a company grows, ensuring reproducibility and replicability for all meaningful experiments, and having the capability to seamlessly rerun (or reuse) code related to old experiments will increase the speed and reduce the frustration of the data science function.
Conclusion
Scaling data science in a scale-up is not a simple task. In addition to the challenges faced across the business (communication, direction and focus, people growth and agility) the data science function has its own unique difficulties. The situation is further complicated by the fact that some of the approaches and behaviours that worked well in the start-up stage are not well suited for this new phase of growth.
I believe that the most important point to remember as the company grows, is to understand clearly why and how the efforts of the function affect the company goals, and then support the people in the teams as best as possible to allow them to deliver solutions with a tangible impact company wide.
